
太久没回来了,今天计划把后台升级一下,然后重新出发…
作者: GIGI WANG
Spark学习笔记
简述
Apache Spark是一个开源集群运算框架,最初是由加州大学柏克莱分校AMPLab所开发。相对于Hadoop的MapReduce会在运行完工作后将中介数据存放到磁盘中,Spark使用了存储器内运算技术,能在数据尚未写入硬盘时即在存储器内分析运算。Spark在存储器内运行程序的运算速度能做到比Hadoop MapReduce的运算速度快上100倍,即便是运行程序于硬盘时,Spark也能快上10倍速度。[1]Spark允许用户将数据加载至集群存储器,并多次对其进行查询,非常适合用于机器学习算法。
Hadoop 和 Spark 的关系
- Hadoop Google 在 2003 年和 2004 年先后发表了 Google 文件系统 GFS 和 MapReduce 编程模型论文. 基于这两篇开源文档,2006 年 Nutch 项目子项目之一的 Hadoop 实现了两个强有力的开源产品:HDFS 和 MapReduce. Hadoop 成为了典型的大数据批量处理架构,由 HDFS 负责静态数据的存储,并通过 MapReduce 将计算逻辑分配到各数据节点进行数据计算和价值发现.之后以 HDFS 和 MapReduce 为基础建立了很多项目,形成了 Hadoop 生态圈.
- Spark Spark 则是UC Berkeley AMP lab 所开源的类Hadoop MapReduce的
通用并行框架, 专门用于大数据量下的迭代式计算.是为了跟 Hadoop 配合而开发出来的,不是为了取代 Hadoop.
Spark 运算比 Hadoop 的 MapReduce 框架快的原因是因为 Hadoop 在一次 MapReduce 运算之后,会将数据的运算结果从内存写入到磁盘中,第二次 Mapredue 运算时在从磁盘中读取数据,所以其瓶颈在2次运算间的多余 IO 消耗. Spark 则是将数据一直缓存在内存中,直到计算得到最后的结果,再将结果写入到磁盘,所以多次运算的情况下, Spark 是比较快的. 其优化了迭代式工作负载.

Spark 的主要特点还包括:
- (1)提供 Cache 机制来支持需要反复迭代计算或者多次数据共享,减少数据读取的 IO 开销;
- (2)提供了一套支持 DAG 图的分布式并行计算的编程框架,减少多次计算之间中间结果写到 Hdfs 的开销;
- (3)使用多线程池模型减少 Task 启动开稍, shuffle 过程中避免不必要的 sort 操作并减少磁盘 IO 操作。(Hadoop 的 Map 和 reduce 之间的 shuffle 需要 sort)
Spark计算框架
伯克利大学将 Spark 的整个生态系统成为 伯克利数据分析栈(BDAS),在核心框架 Spark 的基础上,主要提供四个范畴的计算框架:
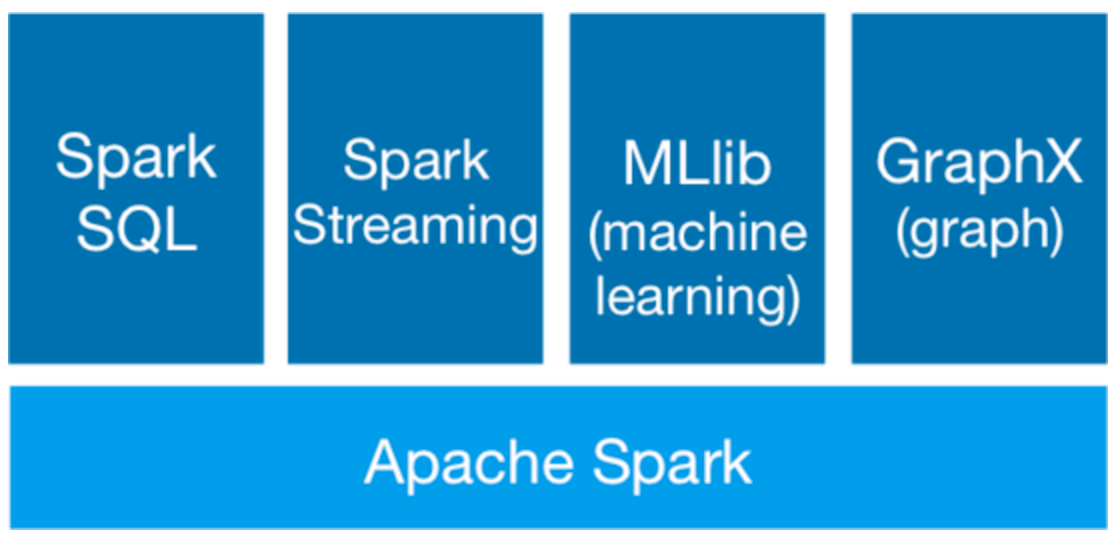
- Spark SQL: 提供了类 SQL 的查询,返回 Spark-DataFrame 的数据结构(类似 Hive)
- Spark Streaming: 流式计算,主要用于处理线上实时时序数据(类似 storm)
- MLlib: 提供机器学习的各种模型和调优
- GraphX: 提供基于图的算法,如 PageRank
系统架构
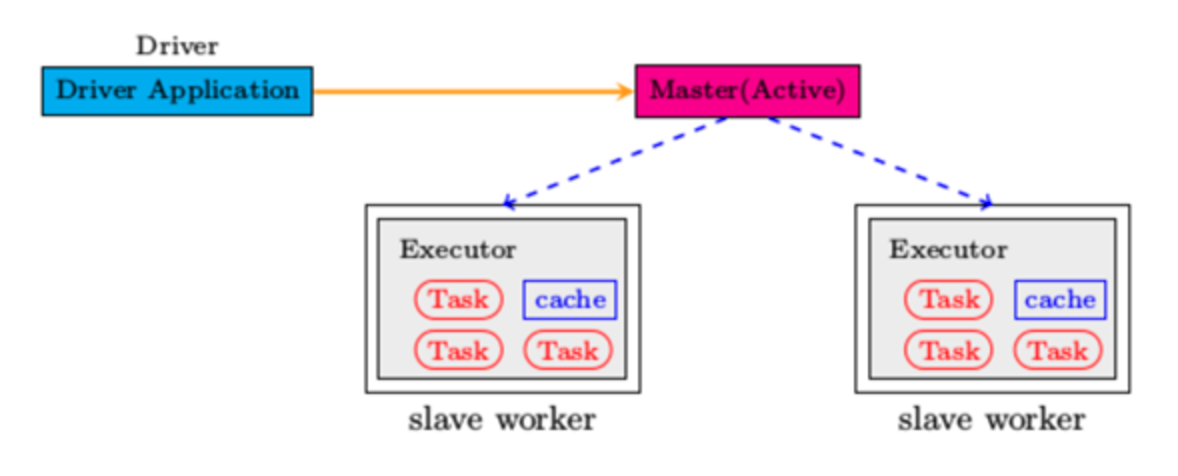
Spark遵循主从架构。它的集群由一个主服务器和多个从服务器组成。
Spark架构依赖于两个抽象:
- 弹性分布式数据集(RDD)
- 有向无环图(DAG)

- 应用程序(Application): 基于Spark的用户程序,包含了一个Driver Program 和集群中多个的Executor;
- 驱动(Driver): 运行Application的main()函数并且创建SparkContext;
- 执行单元(Executor): 是为某Application运行在Worker Node上的一个进程,该进程负责运行Task,并且负责将数据存在内存或者磁盘上,每个Application都有各自独立的Executors;
- 集群管理程序(Cluster Manager): 在集群上获取资源的外部服务(例如:Local、Mesos或Yarn等集群管理系统);
- 操作(Operation): 作用于RDD的各种操作分为Transformation和Action.
底层详细细节介绍:
使用spark-submit提交一个Spark作业之后,这个作业就会启动一个对应的Driver进程。根据你使用的部署模式(deploy-mode)不同,Driver进程可能在本地启动,也可能在集群中某个工作节点上启动。而Driver进程要做的第一件事情,就是向集群管理器申请运行Spark作业需要使用的资源,这里的资源指的就是Executor进程。
YARN集群管理器会根据我们为Spark作业设置的资源参数,在各个工作节点上,启动一定数量的Executor进程,每个Executor进程都占有一定数量的内存和CPU core。
在申请到了作业执行所需的资源之后,Driver进程就会开始调度和执行我们编写的作业代码。Driver进程会将我们编写的Spark作业代码分拆为多个stage,每个stage执行一部分代码片段,并为每个stage创建一批Task,然后将这些Task分配到各个Executor进程中执行。Task是最小的计算单元,负责执行一模一样的计算逻辑(也就是我们自己编写的某个代码片段),只是每个Task处理的数据不同而已。一个stage的所有Task都执行完毕之后,会在各个节点本地的磁盘文件中写入计算中间结果,然后Driver就会调度运行下一个stage。下一个stage的Task的输入数据就是上一个stage输出的中间结果。如此循环往复,直到将我们自己编写的代码逻辑全部执行完,并且计算完所有的数据,得到我们想要的结果为止。
Spark是根据shuffle类算子来进行stage的划分。如果我们的代码中执行了某个shuffle类算子(比如reduceByKey、join等),那么就会在该算子处,划分出一个stage界限来。可以大致理解为,shuffle算子执行之前的代码会被划分为一个stage,shuffle算子执行以及之后的代码会被划分为下一个stage。因此一个stage刚开始执行的时候,它的每个Task可能都会从上一个stage的Task所在的节点,去通过网络传输拉取需要自己处理的所有key,然后对拉取到的所有相同的key使用我们自己编写的算子函数执行聚合操作(比如reduceByKey()算子接收的函数)。这个过程就是shuffle。
当我们在代码中执行了cache/persist等持久化操作时,根据我们选择的持久化级别的不同,每个Task计算出来的数据也会保存到Executor进程的内存或者所在节点的磁盘文件中。
因此Executor的内存主要分为三块:第一块是让Task执行我们自己编写的代码时使用,默认是占Executor总内存的20%;第二块是让Task通过shuffle过程拉取了上一个stage的Task的输出后,进行聚合等操作时使用,默认也是占Executor总内存的20%;第三块是让RDD持久化时使用,默认占Executor总内存的60%。
Task的执行速度是跟每个Executor进程的CPU core数量有直接关系的。一个CPU core同一时间只能执行一个线程。而每个Executor进程上分配到的多个Task,都是以每个Task一条线程的方式,多线程并发运行的。如果CPU core数量比较充足,而且分配到的Task数量比较合理,那么通常来说,可以比较快速和高效地执行完这些Task线程。
在实际编程中,我们不需关心以上调度细节.只需使用 Spark 提供的指定语言的编程接口调用相应的 API 即可.
在 Spark API 中, 一个 应用(Application) 对应一个 SparkContext 的实例。一个 应用 可以用于单个 Job,或者分开的多个 Job 的 session,或者响应请求的长时间生存的服务器。与 MapReduce 不同的是,一个 应用 的进程(我们称之为 Executor),会一直在集群上运行,即使当时没有 Job 在上面运行。
而调用一个Spark内部的 Action 会产生一个 Spark job 来完成它。 为了确定这些job实际的内容,Spark 检查 RDD 的DAG再计算出执行 plan 。这个 plan 以最远端的 RDD 为起点(最远端指的是对外没有依赖的 RDD 或者 数据已经缓存下来的 RDD),产生结果 RDD 的 Action 为结束 。并根据是否发生 shuffle 划分 DAG 的 stage.
RDD
RDD(弹性分布式数据集)是Spark的核心抽象。它是一组元素,在集群的节点之间进行分区,以便我们可以对其执行各种并行操作。
Transformation 和 Action
Spark 的设计思想中,为了减少网络及磁盘 IO 开销,需要设计出一种新的容错方式,于是才诞生了新的数据结构 RDD. RDD 是一种只读的数据块,可以从外部数据转换而来,你可以对RDD 进行函数操作(Operation),包括 Transformation 和 Action. 在这里只读表示当你对一个 RDD 进行了操作,那么结果将会是一个新的 RDD, 这种情况放在代码里,假设变换前后都是使用同一个变量表示这一 RDD,RDD 里面的数据并不是真实的数据,而是一些元数据信息,记录了该 RDD 是通过哪些 Transformation 得到的,在计算机中使用 lineage 来表示这种血缘结构,lineage 形成一个有向无环图 DAG, 整个计算过程中,将不需要将中间结果落地到 HDFS 进行容错,加入某个节点出错,则只需要通过 lineage 关系重新计算即可.

Transformation 操作不是马上提交 Spark 集群执行的,Spark 在遇到 Transformation 操作时只会记录需要这样的操作,并不会去执行,需要等到有 Action 操作的时候才会真正启动计算过程进行计算.针对每个 Action,Spark 会生成一个 Job, 从数据的创建开始,经过 Transformation, 结尾是 Action 操作.这些操作对应形成一个有向无环图(DAG),形成 DAG 的先决条件是最后的函数操作是一个Action
RDD 主要特点
- 1.它是在集群节点上的不可变的、已分区的集合对象;
- 2.通过并行转换的方式来创建(如 Map、 filter、join 等);
- 3.失败自动重建;
- 4.可以控制存储级别(内存、磁盘等)来进行重用;
- 5.必须是可序列化的;
- 6.是静态类型的(只读)。
创建RDD
有两种方法可以用来创建RDD:
- 并行化驱动程序中的现有数据
parallelize - 引用外部存储系统中的数据集,例如:共享文件系统,HDFS,HBase或提供Hadoop InputFormat的数据源
Spark SQL & DataFrame
Spark SQL是Spark用来处理结构化数据的一个模块,它提供了两个编程抽象分别叫做DataFrame和DataSet,它们用于作为分布式SQL查询引擎。
DataFrame
DataFrame(表)= Schema(表结构) + Data(表数据)
DataFrame是组织成命名列的数据集。它在概念上等同于关系数据库中的表,但在底层具有更丰富的优化
DataFrame相比RDD多了数据的结构信息,即schema。RDD是分布式的对象的集合。DataFrame是分布式的Row对象的集合。DataFrame除了提供了比RDD更丰富的算子以外,更重要的特点是提升执行效率、减少数据读取以及执行计划的优化
创建DataFrame
- 方式1:使用case class定义表
- 方式2:使用SparkSession对象创建DataFrame
spark.createDataFrame - 方式3:直接读取格式化的文件(json,csv
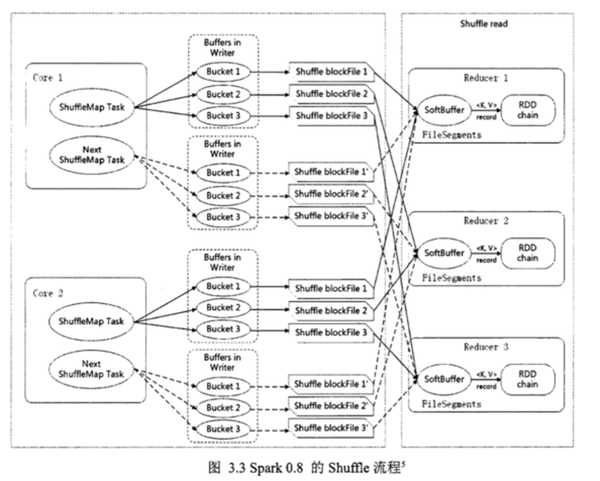
shuffle 和 stage
shuffle 是划分 DAG 中 stage 的标识,同时影响 Spark 执行速度的关键步骤.
RDD 的 Transformation 函数中,又分为窄依赖(narrow dependency)和宽依赖(wide dependency)的操作.窄依赖跟宽依赖的区别是是否发生 shuffle(洗牌) 操作.宽依赖会发生 shuffle 操作. 窄依赖是子 RDD的各个分片(partition)不依赖于其他分片,能够独立计算得到结果,宽依赖指子 RDD 的各个分片会依赖于父RDD 的多个分片,所以会造成父 RDD 的各个分片在集群中重新分片, 看如下两个示例:
// Map: "cat" -> c, cat
val rdd1 = rdd.Map(x => (x.charAt(0), x))
// groupby same key and count
val rdd2 = rdd1.groupBy(x => x._1).
Map(x => (x._1, x._2.toList.length))
第一个 Map 操作将 RDD 里的各个元素进行映射, RDD 的各个数据元素之间不存在依赖,可以在集群的各个内存中独立计算,也就是并行化,第二个 groupby 之后的 Map 操作,为了计算相同 key 下的元素个数,需要把相同 key 的元素聚集到同一个 partition 下,所以造成了数据在内存中的重新分布,即 shuffle 操作.shuffle 操作是 spark 中最耗时的操作,应尽量避免不必要的 shuffle.
宽依赖主要有两个过程: shuffle write 和 shuffle fetch. 类似 Hadoop 的 Map 和 Reduce 阶段.shuffle write 将 ShuffleMapTask 任务产生的中间结果缓存到内存中, shuffle fetch 获得 ShuffleMapTask 缓存的中间结果进行 ShuffleReduceTask 计算,这个过程容易造成OutOfMemory.
性能优化
缓存
Spark中对于一个RDD执行多次算子(函数操作)的默认原理是这样的:每次你对一个RDD执行一个算子操作时,都会重新从源头处计算一遍,计算出那个RDD来,然后再对这个RDD执行你的算子操作。这种方式的性能是很差的。
首先要认识到的是, .Spark 本身就是一个基于内存的迭代式计算,所以如果程序从头到尾只有一个 Action 操作且子 RDD 只依赖于一个父RDD 的话,就不需要使用 cache 这个机制, RDD 会在内存中一直从头计算到尾,最后才根据你的 Action 操作返回一个值或者保存到相应的磁盘中.需要 cache 的是当存在多个 Action 操作或者依赖于多个 RDD 的时候, 可以在那之前缓存RDD.
shuffle优化
- 当进行联合的规约操作时,避免使用 groupByKey
- 当输入和输入的类型不一致时,避免使用 reduceByKey
- 生成新列的时候,避免使用单独生成一列再 join 回来的方式,而是直接在数据上生成.
- 当需要对两个 RDD 使用 join 的时候,如果其中一个数据集特别小,小到能塞到每个 Executor 单独的内存中的时候,可以不使用 join, 使用 broadcast 操作将小 RDD 复制广播到每个 Executor 的内存里 join.
资源参数调优
MacOS上 Virtualbox 设置CentOS 网络
MacOS 安装Virtualbox,CentOS,如何配置网络?
mac上不像windows平台Virtualbox安装后可以自动创建两个虚拟网卡vmnet1 vmnet8,如果需要虚拟机连接互联网,并且可以在mac中来访问虚拟机网络,简单的办法就是创建两个网卡:一个NAT Network,一个HOST only Adpater.
vm界面都提供了直接创建入口,点击创建就可以了,在虚拟机中Adpater1,Adpater2 分别设置好这两个网络.
开机进入CENTOS,看是否能识别到这两个网卡.如果识别到,确认一下网络地址,获取直接配置一个静态地址,一个自动获取:
/etc/sysconfig/network-scripts/
ifcfg-enp0s8 ifcfg-enp0s3
TYPE=Ethernet
PROXY_METHOD=none
BROWSER_ONLY=no
BOOTPROTO=static
IPADDR=192.168.56.100
NETMASK=255.255.255.0
NETWORK=192.168.56.0
DEFROUTE=yes
IPV4_FAILURE_FATAL=no
IPV6INIT=yes
IPV6_AUTOCONF=yes
IPV6_DEFROUTE=yes
IPV6_FAILURE_FATAL=no
IPV6_ADDR_GEN_MODE=stable-privacy
NAME=enp0s3
DEVICE=enp0s3
ONBOOT=yes
重启下网络:
systemctl restart NetworkManager
Git提交信息规范Git Commit Message
目前规范使用较多的是引用或衍生 Github Angular开发中<提交信息准则>章节(Commit Message Guidelines).以下为规范译文:
关于如何格式化git commit消息,我们有非常精确的规则。这样会有更具可读性的消息,在查看项目历史记录时易于遵循。而且,我们使用git commit消息生成AngularJS更改日志。
可以使用典型的git工作流程或使用CLI向导(Commitizen)添加提交消息格式。要使用该向导,yarn run commit 请在对git进行更改后在终端中运行。
提交消息格式
每个提交消息均由信息头(header),正文(body)和页脚(footer)组成。信息头(header)具有一种特殊的格式,包括type(类型),scope(范围)和subject(主题):
<type>(<scope>): <subject>
<BLANK LINE>
<body>
<BLANK LINE>
<footer>
所述信息头(header)是必须的,而信息头范围(scope)的是可选的。
提交消息的任何一行都不能超过100个字符!这使得该消息在GitHub以及各种git工具中更易于阅读。
Revert
如果提交还原了先前的提交,则应以开头revert: ,后跟还原的提交的标头。在正文中应该说:This reverts commit <hash>.,其中哈希是要还原的提交的SHA。
类型(type)
必须为以下之一:
- feat:一项新功能(feature)
- fix:一个bug修复
- docs:仅文档更改
- style:风格,不影响代码含义的更改(空白,格式,缺少分号等)
- refactor:重构,既不修正错误也不增加功能的代码更改
- perf:改进性能的代码改动
- test:添加缺失或更正现有测试
- chore:更改构建过程或辅助工具和库,例如文档生成
范围(scope)
范围可以是指定提交更改位置的任何内容。例如$location, $browser,$compile,$rootScope,ngHref,ngClick,ngView,等…
当更改影响的范围不止一个范围时,可以使用*(星号)标识。
主题(Subject)
主题简要描述了更改:
- 使用祈使句式和现在时:“change”而不是“changed”或“changes”
- 不要大写第一个字母
- 末尾没有点(。)
正文(Body)
就像在主题中一样,使用祈使句式现在时态:“change”而不是“changed”或“changes”。正文应包括改变的动机,并将其与以前的行为进行对比。
页脚(Footer)
页脚应包含有关Breaking Changes的所有信息,也是参考此提交关闭的GitHub问题的位置 。
重大更改应以BREAKING CHANGE:带有空格或两个换行符的单词开头。然后,将其余的提交消息用于此目的。
详细说明可以在本文档中找到。
如何将一台Chromebook打造成办公主力?
自从Google 将Android 集成进Chrome OS, 今年年初宣布将支持Linux,而最近的系统更新又有多款Chromebook设备陆陆续续支持了Linux apps,Chrome OS已经不再缺少apps。
在开发办公上使用chromebook已经没有太多的障碍。

前段时间入手了一台Chromebook,是Acer Chromebook 14(CB3-431).而不是大名鼎鼎PixelBook,因为穷,没有dollar预算。配置嘛就不说了,对于不了解的可以认为就是一坨shit吧。
不过,我觉得这台Chromebook使用起来是相当OK的。使用顺手,价格便宜,还要什么自行车?
办公?开发?使用Chromebook?没错,Office 办公,修个图,或者跑个Python程序,编译个Java… 在行的!总有你需要的App等着你。没有Chrome App 可以选择Android App,没有Android Apps 可以选择Linux Apps!
注意这是在一定范围的。具体还是取决于你的具体工作,对于我或许也个ssh客户端 App 就足够了呢?
首先,我拿到了Chromebook,第一件事是激活使用,众所周知的原因,我要借助某些工具就如同我的手机第一次开机时,借助一台windows上使用一个工具(名字大家都知道),局域网共享代理方式,登录Google账号,完成激活。
第二,开启Google play store,设备支持的话目前直接都可以用。下载必备上网工具,就是上条中说的大家都知道名字的App。这个app的图标是这样的:

当然这个app 也有chrome 版的,相对Android版体验还是差很多,已经好久而且已经不再更新了,linux 版,qt版本就没再尝试,应该也可以用的。
第三,打开 chrome://flags/ ,打开 ARC VPN integration #arc-vpn,这样就能使用那个android app来使用互联网了。
接下来就自由发挥了,chrome app, Android app 还有Linux 的该用什么就安装什么。其实chrome app算是体验最好,但是Google已经给App判了死刑,一个个chrome app 都会慢慢的消失。
这里推荐几款很赞的开发工具吧,可以离线使用,Google系列的就不列了,好找。码字太累。
1.Termius – SSH Client (好用,已停更),这里直达Termius – SSH Client
2.Secure Shell App (官方出品,必备)
3.Caret (文本编辑,IDE)
4.Postman (停更)这里直达:Postman
5.Chrome MySQL Admin
6.Evernote
7.Polarr Photo Editor
我的博客即将同步至腾讯云+社区,邀请大家一同入驻:https://cloud.tencent.com/developer/support-plan?invite_code=144indpg30z1e
Linux Mint cinnamon Crashed…
Cinnamon crashed, running in fallback mode…
Cinnamon 喜欢崩溃这是出了名的,刚刚从ubuntu切换到LinuxMint系统,正在为其简单快速而窃喜。我正想这个系统真棒,集成了这个多软件,操作如此简单。没想到…
当我在安装ibus中文输入法是遇到问题: 安装完成后配置界面打不开,症状是点击无效,终端输入:
ibus-setup
会提示
File "/usr/share/ibus/setup/main.py", line 31, in <module>
from gi.repository import GLib
ModuleNotFoundError: No module named 'gi'
确认发现本机python2.7 python3.6 都没有安装gi库。那就安装了gi, 而貌似gi.repository 并不包含在gi中,就目前版本而言。我安装了pgi 。。。
然后就悲剧了。 而应该是:
sudo apt reinstall python-gi sudo apt reinstall python3-gi sudo apt install python3-pyside sudo apt install python-pyside
安装vmplayer :
https://communities.vmware.com/thread/568089
diff -Naur vmnet-only.orig/bridge.c vmnet-only/bridge.c
— vmnet-only/bridge.c 2017-06-26 22:08:39.148034785 +1000
+++ vmnet-only/bridge.c 2017-07-16 11:37:01.325802125 +1000
@@ -636,7 +636,7 @@
unsigned long flags;
int i;
– atomic_inc(&clone->users);
+ clone = skb_get(clone);
clone->dev = dev;
clone->protocol = eth_type_trans(clone, dev);
nginx php5.3+mysql5.1 redhat6.5 配置记录
同步自:http://www.gejoin.com/2017/12/27/install-php-mysql-nginx-on-redhat6.5-linux-tips.html
一台没有联网但是有安装介质的rhel6.5-x86_64服务器。 计划安装部署上php+mysql 服务。由于有安装介质,光盘上的mysql版本5.1,php 版本5.3.3 ,没办法软件版本老就老了凑合用了。

1.首先挂载上iso光盘
# mount -o loop -t iso9660 /csys/rhel-server-6.5-x86_64-dvd.iso /mnt/vcdrom/
2.安装 php mysql
# cd /mnt/vcdrom/Packages/ # ls -rlt php* mysql* # rpm -ivh mysql*.rpm --nodeps --force # rpm -ivh php*.rpm --nodeps --force
3.编译安装nginx nginx 安装没什么说的,源码nginx-1.12.2编译安装。
# ./configure # make & make install
4.安装一些php依赖包,rhel5.6介质中的包很少的,基本的php-fpm也是没有的。 可以从以下网站获取rpm包:
https://www.rpmfind.net
https://pkgs.org/download
http://rpm.pbone.net/
php-fpm-5.3.3-26.el6.x86_64.rpm php-mbstring-5.3.3-26.el6.x86_64.rpm php-mcrypt-5.3.3-5.el6.x86_64.rpm libmcrypt-2.5.8-9.el6.x86_64.rpm
5.nginx.conf 配置
server {
listen 80;
server_name localhost;
location / {
root html;
index index.html index.htm index.php;
}
error_page 500 502 503 504 /50x.html;
location = /50x.html {
root html;
}
# pass the PHP scripts to FastCGI server listening on 127.0.0.1:9000
location ~ \.php$ {
root html;
fastcgi_pass 127.0.0.1:9000;
fastcgi_index index.php;
fastcgi_param SCRIPT_FILENAME $document_root$fastcgi_script_name;
include fastcgi_params;
}
6.php 配置 编辑/etc/php.ini
session.save_path = “/var/lib/php/session” session.auto_start = 1
# chmod -R 777 /var/lib/php
7.设置服务开机启动
# chkconfig php-fpm on # chkconfig mysqld on
8.启动服务
# service mysqld start # service php-fpm start # /usr/local/nginx/sbin/nginx # mysqladmin -u root password ‘passwd’
9.验证nginx以及php服务
# echo “” > /usr/local/nginx/html/info.php
打开浏览器输入http://REMOTE/
打开浏览器输入http://REMOTE/info.php
10.安装phpMyAdmin 下载并解压phpMyAdmin-4.0.10.20-all-languages.tar.gz,建立到/usr/local/nginx/html/的软连接。 注意phpMyAdmin 支持的php版本。
UEFI模式下RemixOS+Win10 启动项修改
主题:UEFI模式下RemixOS+Win10 启动项中顺序及超时修改
如果win10 是HDD UEFI安装的而非U盘安装,使用Remix官方的安装工具安装后,默认启动Remix OS,菜单超时时间30s. 由于RemixOS 启动使用grub.cfg,而该文件安装在引导分区。这里给出最简单最快的方法,不依赖第三方软件:
- Win +X (A) 进入管理员命令行模式
- 执行以下命令:
mountvol B: /s cd B:\boot\grub B: notepad grub.cfg
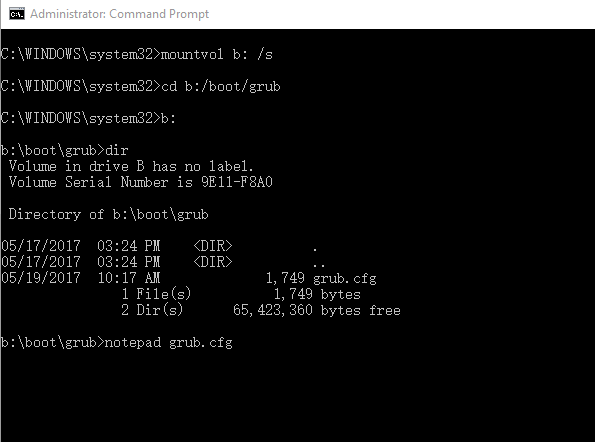
- 在打开的记事本中添加修改:(设置默认windows 1o 启动,超时时间10s)
set default=0 set timeout=10
- 保存退出,执行
mountvol B: /d exit
- 重启看看效果。
ngnix and fastcgi and cicstg 开发环境搭建
一个搭建HTTP Server的项目需求,虽然方案没有最终确定,使用Ngnix做代理转发,后端使用使用开发语言无关的CGI应用进行业务逻辑处理,初步技术是可行的。但使用C语言开发WebServer 应用或许真不是什么好主意,那这样想啊,我们还用CICS这么古老的东西呢?–这里又忍不住想吐槽cics了..这个架构中的毒瘤!…. 进入正题吧,首先安装ngnix,ngnix的强大就不用叨叨了,安装也相当顺利。
- 下载安装PCRE
# wget ftp://ftp.csx.cam.ac.uk/pub/software/programming/pcre/pcre-8.39.tar.gz # ./configure;make;make install;
- 下载安装nginx->[这里]
# wget http://nginx.org/download/nginx-1.10.2.tar.gz # ./configure;make;make install;
这样就可以启动nginx,默认安装在了/usr/local/nginx目录下.
- 下载安装spawn-fcgi,可以从Github Lighthtpd项目中下载,也可以直接从lighttpd.net这里下载。同样可以编译出
Spawn-fcgi这个可执行程序。ngnix是支持FastCgi的,但是没有这个CGI管理程序。 - 接下来就可以写CGI程序了,可以使用一些现成开源库,当然也可以自己写。
- 安装CICS TRANSACTION GATEWAY,!!!NOTE!!![这玩意基本上支持32系统,安装时也会各种水土不服的,你可能需要32位的jre..]安装开发中可能需要32位支持,比如:
libXp.i686 glibc-devel.i686
–慢慢享受其中的酸爽吧%$%$%.
- 顺利的话应该可以写代码测试一下了。以下代码片段是接受从浏览器提交的表单然后提交CTG请求,编写代码编译。
while (FCGI_Accept() >= 0) {
memset(sBufIn,0,sizeof(sBufIn));
FCGI_fread(sBufIn, sizeof(char), sizeof(sBufIn), FCGI_stdin);
if(strlen(sBufIn)==0)
{
memcpy(sBufIn,sParmas,strlen(sParmas));
}
memset(&tHttpIn,0x00,sizeof(HttpReqT));
rc=InitHttpIn(&tHttpIn,sBufIn);
resultSize= URLDecode(tHttpIn.MsgIn, tHttpIn.MsgIn, sizeof(tHttpIn.MsgIn));
rc=CallCtgSvr(&tHttpIn);
if(rc != RC_OK)
{
printf("Content-type: text/plain\r\n"
"\r\n"
""
"QUERY_STRING :%s.\n"
"REQUEST_METHOD : %s.\n"
"CONTENT_TYPE : %s.\n"
"CONTENT_LENGTH : %s.\n"
"SERVER_PROTOCOL : %s.\n"
...
}
...
}
// CTG 调用函数
// CTG_openRemoteGatewayConnection();
// CTG_ECI_Execute(gatewayToken, &eciParms);
// Makefile libs -m64 -lctgclient -lfcgi
- 配置nginx 端口转发处理FASTCGI.
location ~ \.cgi$ {
fastcgi_pass 127.0.0.1:8000;
fastcgi_index index.cgi;
fastcgi_param SCRIPT_FILENAME fcgi$fastcgi_script_name;
include fastcgi_params;
}
- 配置nginx 端口转发处理FASTCGI.启动CGI程序。
/usr/local/nginx/sbin/spawn-fcgi -a 127.0.0.1 -p 8000 -f /usr/local/nginx/cgi-bin/ctgcls
- 使用浏览器测试或其他HTTP 客户端程序测试
#!/usr/bin/env python
#coding=utf8
import httplib, urllib
httpClient = None
try:
#params = urllib.urlencode({'name': 'tom', 'age': 22})
params = '''TEST CTG..'''
headers = {"Content-type": "application/x-www-form-urlencoded", "Accept": "text/plain"}
httpClient = httplib.HTTPConnection("192.168.101.181", 80, timeout=30)
httpClient.request("POST", "/ctgcls.cgi", params, headers)
response = httpClient.getresponse()
print response.status
print response.reason
print response.read()
print response.getheaders() #获取头信息
except Exception, e:
print e
finally:
if httpClient:
httpClient.close()
[Sovled]CM13 can NOT sync contacts-CM13无法同步google联系人
Nexus 5刷完cm13+opengapps(pico) 之后,goolge服务,google play store 等应用都有了,可以正常登录google账号,但是打开CM13自带的联系人应用则空空如也,只能选择添加账号。选择添加账户,只有Exchange选项,并没有Google选项!!可是Google账号明明已经成功登录了!?
BUG/Problem:CM13(CyanogenMod) Missed Google Contacts option and can not sync,when flashed cm13+opengapps(pico) and login in andriod system.There is nothing but ‘add account’ or ‘import new’ option when Opening the CM13 stock Contacts app. Enter add account menu,there is no Google option do not like other phones or other system.
![]()
通过对比一台正常手机,发现刷入的Gapps少了Google Contacts Sync这个服务。需要安装这个APP,选择正确的版本下载,安装。
下载地址:http://www.apkmirror.com/apk/google-inc/google-contacts-sync/
HowToSolve:You should download ‘GoogleContactsSync.apk'(com.google.android.syncadapters.contacts) and install it. Download this apk here: http://www.apkmirror.com/apk/google-inc/google-contacts-sync/
重启下手机后,打开联系人应用,选择添加,Google 选项回来了,再看看你的Google联系人是不是都回来了!
如果有必要(5.0以上系统)记得更改APP权限,联系人以及联系人同步App授权给Contact读取权限。

And then restart your phone,when you done,open the contacts app,your contacts would list there.
没有深究是CM13还是GApps问题,但是,个人觉得CM已经不是从前的CM了。。
In my opinion,Cyanogenmod is not which used be.
By GIGI WANG.